Few-shot Learning Goes Multilingual
This blog shares a recipe for creating few-shot models localized to languages outside English that you can train on commonly-available hardware and deploy on your laptop.
Tl;dr: if you came just for the guidelines, jump right into The recipe 🍜 section!
I am sure that you've caught some of the buzz around OpenAI's GPT-3 language model. Contrary to the conventional ML models, to train a GPT-3 for a new task, you do not need to update the model (which is quite handy since you'd need an HW worth more than a million dollars to do that :)
Then, how do you teach a GPT-3 a new task? You give it natural-language instructions or very few examples (say, 2 or 3) of inputs and what you expect as outputs.
To train GPT-3 a new task, you do not need to update the model, just natural instructions, or a few examples of input-outputs.

Why is this so powerful? Because this approach avoids the most complex, risky, and of course, costly steps in data science projects: (1) collecting data and (2) training a custom model. Everyone can now train the model to do something very niche that's useful only for you!
Still not impressed? Look at the examples of what niche means in practice:
So now that we have a model that can understand and perform new tasks with data efficiency comparable to humans, you might be wondering, why are all the data scientists (and web developers) still coming to work? :) As usual, there are some gotchas:
- GPT-3 has 175 billion parameters, which is roughly 1000x more than "traditional" NLP models — and this sheds heavily on the model's speed. BLOOM, a recently-released open-source alternative of GPT-3, require 768 GB of RAM, and the prediction of a single token of possibly quite long answer takes several minutes :(
- In training, GPT-3 was fed with a decent portion of the internet, where English is the dominant language. But what about other languages? Would the scraped subset of the internet in our target language be sufficient to learn the few-shot ability? And either way, how does one get a dump of the whole, say, Spanish internet and pass it through a model of comparable size?
From this perspective, the goal of training smaller and/or multilingual instances of GPT-3 sounds a bit impossible.
First, a few assumptions
What do we know about how these Huge Language Models learn from a few examples?
In fact, not so much. GPT-3 is trained on a Causal Language Modeling task, where the objective is to learn to predict the following token in an arbitrary piece of text (we have a lot of random texts on the internet), called Causal Language Modeling (CLM):
Input: "Something like [MASK]" → Correct output: [MASK] = "This".
This does not really resemble the format of in-context few-shot learning:
"{input text1} → {output text1}, {new input text} → [MASK 1..n]"
It seems like the emergent ability of Huge LMs to perform few-shot learning of new tasks is really just a side-product of vast amounts of data and parameters that causes something like a general language understanding.
But it turns out that this is far from true; even Huge LMs make silly errors: Liu et al. (2022) show that if you shuffle the demonstrations, the accuracy of LM's few-shot prediction can rapidly decrease. Min et al. (2022) show that if you replace true predictions of few-shots with meaningless ones (such as predicting "cat" and "dog" instead of "positive" and "negative" to restaurant reviews), the performance of the model remain similar, suggesting that the LM don't even understand (and consider) the labels' meaning.
This leads us to a few assumptions that we build our research on:
- Huge Few-shot LMs do not understand the "meaning" of few-shots. Instead of assuming a certain level of general intelligence, we speculate that few-shot learning on new tasks works because the network has seen a minor portion of the dataset, where learning to follow some prescribed pattern helped to improve the CLM objective. The fact that this small portion got it this far is only allowed by the GPT-3’s enormous capacity.
- Few-shot can be learned supervisedly. The task of "learning to learn" can still be formulated as supervised learning if we set the problem in a format consistent with the prediction. If our explanation of Assumption 1 was right (but not only if), then direct training in the "few-shot" format would also work well with much smaller models. But we need to be careful not to train the model to merely perform a task (or tasks) that we iterated in training — we'll cover that later.
- Multilingual LMs are natively able of cross-lingual transfer. This means that the model can improve accuracy on a task in one language by utilizing (relevant) knowledge obtained from the other. This is a necessary condition for training the models of usable quality in lower-resource languages with much fewer data and even annotated tasks than in English.
Note that at the time when we started experimenting, these assumptions were built vaguely from our few years of experience with large language models rather than from any rigour induction.
The recipe for cooking your few-shot model 🍜
Here's a sequence of steps that you can follow to train a few-shot model in your language. We complement the recipe with a set of known constraints and our observations.
Tl;dr: If you have a Question Answering dataset in your target language, you are most likely good to go with just changing the input texts in our training script.
1. Pick a training task & dataset in your desired target language

The difficult part is right at the beginning. Your dataset should comply with the following conditions:
- The format of your task (not the data itself) should be general enough to cover any possible application of your few-shooter. If it's possible, we recommend directly using or formulating the task as a Question-answering, but be careful to leave the domain of the inputs open and not to introduce any new bias (see below).
- Avoid datasets with known prediction biases, where the true output can be too often exploited by a simple heuristic. In QA datasets, this can, e.g. be a heuristic of always predicting the first noun of the first sentence — that often works pretty well.
More generally, you want the model to need to use all the input. This is especially relevant if you construct your open-ended dataset from a close-answer task(s), like classification or named entity recognition —otherwise, you could unintentionally train the model to, e.g. always return the personal name in the input for any question starting with "Who".
Note that it is likely that your target-language dataset will have qualitative issues, like a small size (say, only a few thousand examples) or some biases, nevertheless. In our scenario, we used the Czech QA dataset SQADv3.0 of 10k question-context-answer tuples. We are aware of some rather serious disqualifies of this dataset: for instance, most questions can be answered by using only the first or second sentence.
Don't give up — we have seen that the target-language dataset is there mainly to get the model used for the template of the input and the generation in the target language. Still, the heavy lifting here is done by what we call a transfer dataset.
2. Pick a large & quality "transfer dataset"
A transfer dataset is there to capture the learning-to-learn task in as much broadness as possible. While this dataset will likely be much bigger than your target-lang dataset, we find that quality is much more than quantity here — we obtain substantial improvements by using a more complex QA dataset, AdversarialQA, with 30k samples, compared to 88k SQuAD.

If you cast your target-lang dataset into the QA format, you can use exactly the same approach as us. But note that likely, you can do even better if you take extra steps to include more diverse tasks into the training. With a broad knowledge of the NLP datasets, you can do that quite easily; For instance, using the Promptsource library, intended to provide a common interface to cast many NLP datasets into the sequence-to-sequence format.
3. Evaluate
Eventually, you will want to evaluate how well you are doing on one or many of your desired task(s), so why not do that already during the training? Once your training is done, you'll also have the prediction routine ready for the final model.
We find that the optimal training duration varies depending on the proximity of your target task(s) from the domain of your training texts — if your application(s) are close to the next articles of SQuAD, you might want to "overfit" a bit, while more distant tasks will feel best served by the most general model possible, that will probably occur earlier in training.
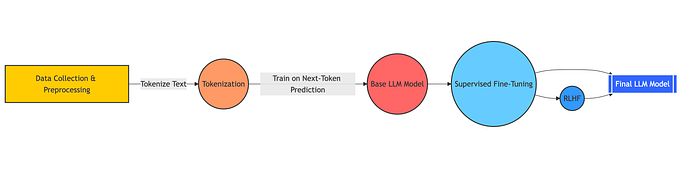
4. Train
At this point, we'll just pick a suitable model pre-trained for our target language, perhaps on CLM or sequence-to-sequence generation objective. A good idea is to try mBART, or mT5. We opted for mT5-Base and mT5-Large.
Remember to keep the chosen input template when constructing training samples. These will look like this:
Input:
"Question: {Q_1}, Context: {I_1}, Answer: {A_1}, […],
Question: {Q_2}, Context: {I_2}, Answer: {A_2}, […],
…
Question: {Q_pred}, Input: {I_pred}, Answer: " → Target: "{A_pred}"
We think that you can make it easier for the model to respond in the right language if you localize the instruction strings ("Input", "Question", "Answer") into the language of your dataset, but we have not really measured this.
Perhaps it is a good idea to pick a number of demonstrations i (in {Q_1..i}, {I_1..i}, {A_1..i}) by your preferred usage. Though the performance does not seem to differ much, it might still be better to remain roughly consistent between the training and evaluation.
How to pick the demonstrations? That is a good and important question that we'll take a look into in Refinements below ⬇️ ;) At this point, you can as well pick the demonstrations randomly.
As a side note, we also experimented with extractive encoder models, like XLM-RoBERTa, that would be a much faster few-shooter, but found that encoders are really resistant to improvement using the demonstrations. It somehow seems that few-shot ability is conditioned by the generative pre-training.
And that's it! 🍲
If you still miss some ingredients in the recipe, or you don't know which one would fit the best, you can check how we did it in our implementation or chat with us in the comments below ⬇️.
Refinements: Harder Demonstrations sampling
A common issue of few-shooters, either trained explicitly for few-shot or not, is a low sensitivity to demonstrations. Min et al. (2022) show that few-shooters use the demonstrations mainly to learn the template of the task.
We argue that this might be a consequence of a random selection of demonstrations in training, picking the demonstrations that are relevant for prediction only by sharing the input format. For instance, given that there is little shared semantics between very diverse questions of QA datasets, models are not really motivated to look for any semantic features shared among demonstrations. Instead, they stick to the only feature that is always informative for the prediction: a task template.
What can we do with it? We need to replace random demonstrations with others that are informative for the prediction! But we also need to be careful not to make it too easy because, in practice, our demonstrations will still be selected randomly. In other words, the model should use the demonstrations as much as possible whenever it helps, but not as much as to draw false presumptions from them.
We replace random selection of demonstrations in training with informative ones, but we make sure not to make the task too easy.
- Informativeness: How can we say which samples are mutually informative? Currently, we can't :) But we can at least increase the chance of co-occurrence of the "relevant" demonstrations with a possibly benefiting prediction. In QA, we do this by clustering the questions sharing the same question word: I.e., together with a "Who" question, we show the model the other two questions and correct answers to a "Who" question.
- Non-triviality: At the same time, we want to avoid trivial cases, e.g. where we'd ask the model to simply copy-paste the answer from a demonstration. We do this by ranking a random draw of the same-cluster demonstrations by their difficulty, where the difficulty corresponds to a conditional probability that the model will generate a correct answer: the lower is the probability, the "harder" is the demonstration.
This rationalisation might sound a bit far-fetched. Therefore, in the evaluation below, we also focus on the impact of this refined demonstration selection on the selected end task.
Case study: How good is the final few-shot model?
Evaluation of the model purposed to learn an arbitrary new task from the input is a tricky thing. Clearly, the model will not excel exactly well in any task. What does it depend on?
Perhaps not too surprisingly, we quickly find that the important determinant of our few-shooter's quality is the proximity of the input text's domain to the QA training data. Hence, it would not be really fair to compare our model to GPT-3, or a standard supervised model on news articles, that our training QA datasets were built from.
Similar to us, you might find that the selection of datasets in languages outside English is limited — looking for an annotated dataset in Czech, most of the datasets are built from Wikipedia (identically to our target-language QA dataset) or in news articles. The most distant publicly-available dataset was an annotated NER dataset from radio transcripts, where still, all of the entities (names, places, dates, etc.) occur commonly in Wikipedia and hence, in our QA.
That's why we share the evaluation on an own-annotated dataset that we collected for a real-world application of entity recognition in processing customer email requests on insurance reimbursements. This dataset has a strange but quite consistent structure of the text (requests), uses a lot of domain-specific slang (such as “contract binding”, “reimbursements”, or “vinculation”), and the entities will rarely occur in the training QA datasets (phone numbers, contract numbers, or accident ID). Overall, we have ~1500 emails containing 2913 entities in total.
Evaluation
How do we apply our trained few-shooter for Named Entity Recognition? First, we formulate one or a few questions formulating our request for a chosen entity type that the model understands. E.g. for clients’ names, we ask, “What is the personal name of the client?” or “What is the customer’s personal name?” In the context of in-context learning, these questions can also be called prompts or instructions.
Then we randomly pick a few contexts of the searched entity and the entity values as input-output demonstrations of the task in the preceding context for a current prediction (see Fig. 2 if it does not sound familiar) and collect the model predictions. Both our questions and inputs are in Czech.
Results 🥁
Our evaluation seeks to answer the following questions:
- How much can the model learn from context? Here, we compare the performance of a generic QA model (zero-shot setting) to a few-shot learner.
- How much does the transfer dataset quality matter? Given the usually low quality of target-language datasets, we wonder how useful it is for the model to improve the "good" dataset in the transfer language (en). Hence, we measure the performance difference between using "easier" SQuAD and "harder" AdversarialQA as the transfer dataset.
- How much does the "few-shoots" sampling method matter? In Refinements, we argue that picking informative demonstrations could make the model more considerate of the demonstrations' semantics. We assess what difference it makes compared to the random sampling used in the previous work.
- How much better is it to use larger (but slower) models? Our objective is to deliver much smaller in-context learners, but still, we acknowledge that more expressive models will probably help. We measure what difference it makes if we use mT5-Large (1.3B params) instead mT5-Base (580M params).

Figure 4 shows that using even three examples can make a big difference. Dataset selection and model size also add ~10% points each. Compared to these, hard sampling seems to add only a few points (presumably, it's 3% out of 11% gained by Dataset & sampling change), but it's nice that this gain is complementary to harder dataset selection. It is really cool that our Czech in-context learner outperforms the 2913-sample supervised performance with only 21 samples and no updates, but we also note that our few-shot large model is 12x larger (and hence, also slower).

Figure 5 evaluates our best-performing smaller and larger model over all our prompts and entities, as compared to the supervised baseline. Compared to the previous work, we find that our sampling method makes our model relatively insensitive to the specific prompts formulation. It seems that the large model is much better at learning unseen entities w.r.t. QA datasets and can also be better at cross-lingual prompts. Still, both models might fall behind the supervised model on the distant entity types that do not seem difficult to learn but apparently are for our few-shooter (emails and phone numbers), suggesting that our model is not really good at working with structural characteristics of entities.
Wrap up 🎁
In this blog, we share a recipe 🍲 for creating few-shot in-context learners for languages outside of English. In our use case, we found that our freshly-cooked few-shot models for En+Cze (Small and Large) can work comparably or even better than a supervised encoder trained on ~2900 samples while being more than 100-times smaller than GPT-3.
While it is not in our power to train compact few-shooters for hundreds of widespread world languages, we hope to encourage researchers and practitioners to create and share general-purpose models that can save hundreds of hours of tedious work of collecting annotations for the myriad of NLP applications!
Feel free to play with our En+Cze models on 🤗 Hugging Face Models hub!